Mark24
Roda源码分析(二)请求响应
前言
大家好,我是MARK24 。可以叫我 MARK。这是我研究Roda的笔记。
这是我研究Roda,做的记录。水平有限,欢迎指正。
主要分为两篇以及有价值的引用,相关系列目录:
研究的Roda源码版本 2022年2月9日 Roda v3.52.0 dc600b763ebf4f15e11c0428e26b812b9d140911
阅读本文章,你可能获得
- Rack 应用概念的了解
- Roda 树形路由的原理
- Ruby Class中 extend、include 的技巧
- Ruby 中 catch、throw 的使用
- 阅读源码的方法
以及欣赏 Roda 的设计等。
我个人水平和精力有限,研究Ruby时间不长,自认还是个小学生。如有错误欢迎指正,欢迎交流~
一、预备知识:Rack工作原理
熟悉的可以跳过 Rack 部分。
Roda本质上还是有一个 Rack 的应用。用户请求发送至我们的服务器,首先经过 Rack,所以先要明白 Rack的工作原理。
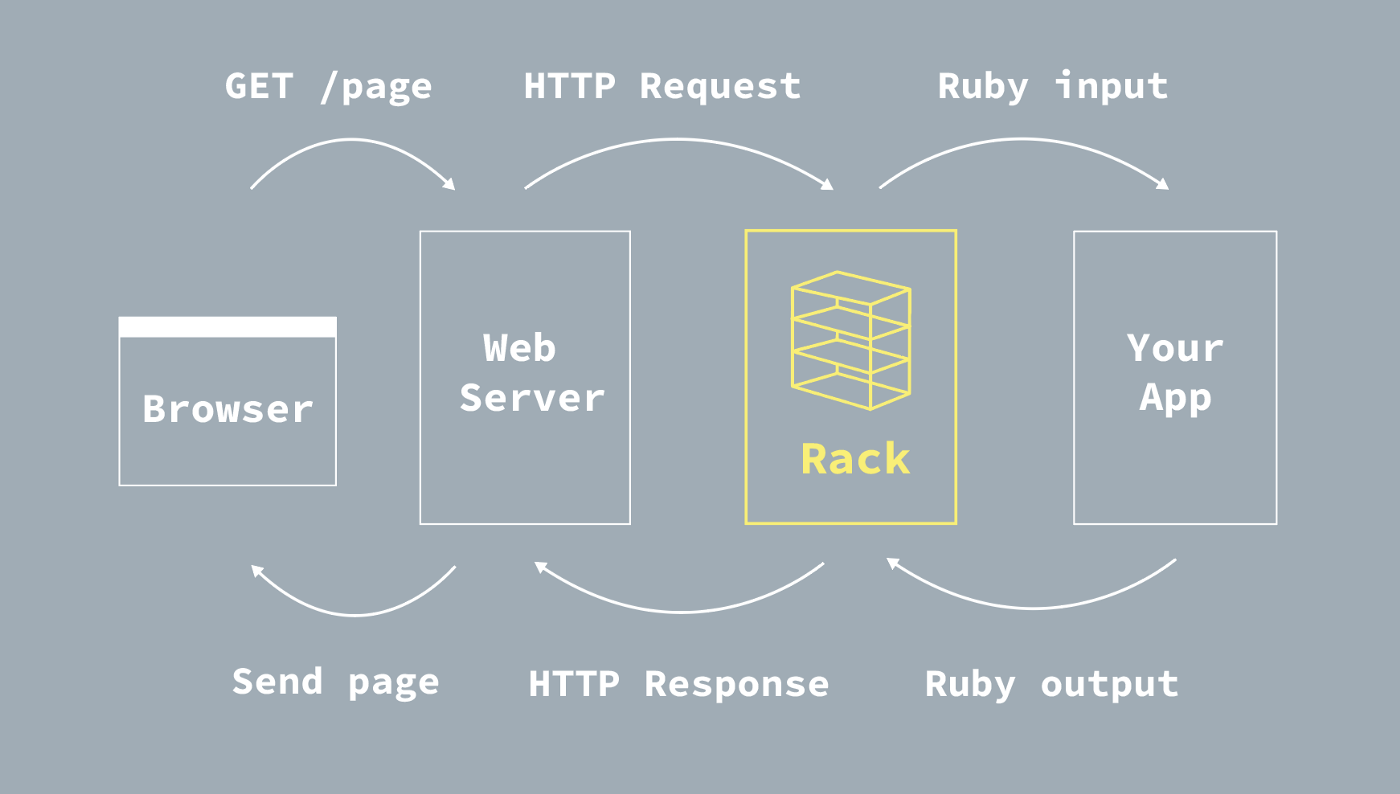
这篇文章简单的介绍了 Rack的工作流程
想要深入了解 Rack 可以查看官网源码
有一部国人编写的笔记也可以提供很大的帮助,可以下载:【RackProgram.pdf 】
二、研究方法总结
Roda只是一个研究对象,研究方法是通用的。
1.把握宏观,要分清楚几个大类,每个方法在哪个大类下工作,决定了理解他们的角色
大概只需要关注,大类、和 initialize 方法。这里决定了他们初始化的值。
可以理解未来都是围绕着 initialize 里面的数据。
2.从入口开始往上找调用方法看看调用关系
阅读代码不应该从代码层面的 从上往下读。这是错误的。
根据语言的运行特点,以Ruby为例。应该以 解释器或者编译的运行顺序来观察源码。
1)代码初始化,进行了什么
class类声明、以及类中可执行语句在运行。可以关注下 class 中 initialize 中声明的变量,以及动态生成的代码。(Ruby和其他语言不一样,class内部也有代码在运行,你应该知道的。)
2) 入口开始,调用关系
建立完内存中初始化的 class 等对象。就可以站在程序运行的角度,从入口调用的顺序 依次查看源码。
3.分析工具
主要使用他们的一些功能帮助阅读。有人可能觉得 DEBUG 工具就够了,我的体会不是这样,DBEUG 的切入点太细碎,而且不够准(我总是这个感觉)。跳转的地方往往涉及面太广,出错了要再次重来。当然可能我不会用啦。不过这些不重要。
真正重要的部分其实是明白Ruby工作的机制,以及按照Ruby运行的规律,去解读源码的主要部分,识别作者的意图。我觉得这个才比较重要。
1)VScode 编辑器
- 全局搜索变量、函数定义
- 查看单个代码文件的 大纲(Outline)即 类、方法 定义一览
2)RubyMine(或者一款IDE)
- DEBUG 功能,可以查看过程(不过这不是万能的,因为 DEBUG 对窥探全局并不好用。实际结果还是要以阅读为主)
- 跳转定义或者使用
- 修改我们使用的 lib库 即 Roda 源码,验证自己的猜想(动态语言的优势,一切都是透明的。使用完可以重新安装)
3) 草稿纸
记录重要的引用关系,记录分析和思考。
三、Roda中使用的Ruby的知识
1.class的上下文中,attr语句会执行、@语句会执行、def语句会注册但是不会执行(实例化被实例调用执行),class上下文的 define_method 会执行
2.def 首次运行只注册不允许,具体的 def 的方法调用顺序,根据 启动app的顺序依次调用
3.Ruby的对象模型,以及 extend、include
这部分主要看插件系统好了。作者在 Ruby 的模型基础上巧妙使用他们构建了自己的插件系统。
4.cath和throw
比如源码的这部分
其实相当核心, 我单独介绍了一下 cath 和 throw 的使用
四、Roda 的运行流程
4.1 大致的宏观描述
Roda主要做四部分工作也对应着他的三个核心类、和一个插件系统
- class Roda
- class RodaRequest
- class RodaResponse
- Plugins
1.class Roda & Plugins
其中 class Roda 的代码非常少,主要起到一个协调和名字空间的作用。
主要的代码 在 roda/lib/roda.rb#L29 把主要的路基都放在了 module Base 中。
为什么这样做? 因为 如果在 Roda 的 class 上下文中定义自己的类方法、实例方法,会成为最高优先级,会覆盖自己的祖先类。
于是 Roda 使用了一个小技巧,把自己的 行为 封装在 Base 模块中,也当成插件 expand 进来。
这样插件也可以被 expand, 这样就可以实现 插件对 Roda 的方法进行覆盖、或者添加方法,从而实现了插件机制。
2.class RodaRequest
RodaRequest 继承自 Rack::Request 主要添加了 Roda 特色的 路由方法 route.on/is/get/post 等,还有匹配路由的适配器。
3.class RodaResponse
RodaResponse 继承自 Rack::Response
4.2 响应过程
4.2.1 生成响应的RackApp
我们知道要想成为 Rack 的应用,必须实现一个 call 方法。这部分可以参考 Rack 的工作原理。
Roda 作为 Rack 应用要遵循这套。
Roda 在 Base 的 ClassMethods 实现了 call 方法
# https://github.com/Mark24Code/roda/blob/master/lib/roda.rb#L52
def call(env)
app.call(env)
end
call方法的调用方式是 返回 app.call(env)
我们寻找 app 是一个方法:
# https://github.com/Mark24Code/roda/blob/master/lib/roda.rb#L33
def app
@app || build_rack_app
end
他返回了一个 @app || build_rack_app
这是一个技巧就是 如果 @app 有值即返回,无值 则 构建一个 rack_app,我们再看看 build_rack_app 方法做了什么
# https://github.com/Mark24Code/roda/blob/master/lib/roda.rb#L388
# Build the rack app to use
def build_rack_app
app = base_rack_app_callable(use_new_dispatch_api?)
@middleware.reverse_each do |args, bl|
mid, *args = args
app = mid.new(app, *args, &bl)
app.freeze if opts[:freeze_middleware]
end
@app = app
end
做的事情就是 去构建一个 Rack 应用。把中间件套成 app 并且返回。
其中又用到了一个方法 base_rack_app_callable
# https://github.com/Mark24Code/roda/blob/master/lib/roda.rb#L378
# The base rack app to use, before middleware is added.
def base_rack_app_callable(new_api=true)
if new_api
lambda{|env| new(env)._roda_handle_main_route}
else
block = @rack_app_route_block
lambda{|env| new(env).call(&block)}
end
end
这里似乎运行到核心了,在这里我们要 返回一个基础的 Rack App 而这个基础的 App是:
# https://github.com/Mark24Code/roda/blob/master/lib/roda.rb#L380
lambda{|env| new(env)._roda_handle_main_route}
new 方法等于隐形的调用 self 即 Roada自己。这里等价于
Roda.new(env)._roda_handle_main_route
这样我们就明白了,原来绕来绕去要生成的基础 Rack App 竟是我自己。
Roda 的初始化函数,来自于前面提到的 Base module
他是被 include 到 Roda 中才会发挥作用的,没有直接定义。
# https://github.com/Mark24Code/roda/blob/master/lib/roda.rb#L485
def initialize(env)
klass = self.class
@_request = klass::RodaRequest.new(self, env)
@_response = klass::RodaResponse.new
end
哈哈这里面做的事情其实也挺简单,记录了自己的 class,生成了一个 @_request、@_response
这里就是另外两个重要的类罢了。
额外提一嘴,之所以用下划线开头,这是一个技巧就是暗示这是内部变量,减少名字冲突的。 Python里面更常见,还喜欢用双下划线。
如果认真了解了 Rack 工作原理,到这里大概就明白了,或者能猜到 Roda 后面要做什么了。
他要做的就是 拿到 RodaRequest 这里携带了 Rack传递过来的环境变量 env。
每一次的用户请求,都会创建一个 Rack App 实例,进而创建一个 RodaRequest 实例,携带请求的 env,这里有一些 UA、HTTP_PATH 之类的消息。
我们要做一些工作,比如路由处理,一些中间件处理。
然后访问数据库,获得数据,然后把结果 写入 RodaResponse 返回给 Rack。
这就完成了 RackApp 的一次工作循环。
4.2.2 处理路由
我们讲完生成 Rack Base App 的事情,别忘了,他还调用了一个 方法 _roda_handle_main_route
那么 _roda_handle_main_route 从名字上看就是处理主路由。来看看它是怎么执行路由的。
Roda 特别的就在于他的 树状结构的路由。下面让我们看下:
# https://github.com/Mark24Code/roda/blob/master/lib/roda.rb#L493
# Handle dispatching to the main route, catching :halt and handling
# the result of the block.
def _roda_handle_main_route
catch(:halt) do
r = @_request
r.block_result(_roda_run_main_route(r))
@_response.finish
end
end
其实这句很关键,几乎可以说,这句直接闭环了整个Rack流程。
block_result是一个方法,他的作用就是判断返回是字符串就按照规定写入 @_response.body,不符合的返回报错。空返回则 返回 nil 这个会触发 404 中间件工作。
这里就是 获得 request对象,传入路由,进行求值,然后把返回传递给 response 对象,完成了整个 Rack的流程。
这里面使用了 catch、 throw。我大概描述下,这部分有趣的可能需要后面展开才会知道。但是不妨碍我在这里提一嘴为什么这里非要用 catch&throw 包裹程序。
一个简单的 Roda程序看起来像这样:
require "roda"
class App < Roda
route do |r|
r.on "a" do
r.on "b" do
r.on "c" do
# /a/b/c
puts "hello world"
end
end
end
end
end
简单说,Roda 处理路由看起来就像是一个 一环扣一环的调用。
它先匹配到 “a” 如果 “a” 匹配路径,就会执行 它的块,即 “b” 部分,然后再匹配 “b” 以此类推。只要匹配中,就对他的块求值。
我们知道,块 是 Ruby特有的概念,但是实际上在底层,他的工作方式看起来就像一个 匿名函数 lambda。
这里就像一个一个函数彼此链式的调用。一直到触达最底层,比如 C。
在 Ruby 的视角这是个深层嵌套的字面解构了。我们想从 “c” 处直接返回,这是用就使用到了 catch、throw技巧。 别忘了,我们可是在最外侧,早已注册了 catch(:halt)
# https://github.com/Mark24Code/roda/blob/master/lib/roda.rb#L493
# Handle dispatching to the main route, catching :halt and handling
# the result of the block.
def _roda_handle_main_route
catch(:halt) do
r = @_request
r.block_result(_roda_run_main_route(r))
@_response.finish
end
end
我们只需要在 内部,不论多么深的嵌套里面调用 throw :halt, response_value 程序就会跳出来,并且携带者我们的 response_value 作为返回值。这个效果有点像其他语言的 goto 。
好了,我们已经大致描述了其实最关键的流程了。下面来详细看下 Roda 如何做到这些的。继续分析 _roda_run_main_route 方法。这是 被 _roda_handle_main_route 调用到的方法。
# https://github.com/Mark24Code/roda/blob/master/lib/roda.rb#L517
# Run the main route block with the request. Designed for
# extension by plugins
def _roda_run_main_route(r)
_roda_main_route(r)
end
源码的注释顺便告诉我们这是一个预留的接口,可以给插件做拓展。不影响我们继续看 _roda_main_route
# https://github.com/Mark24Code/roda/blob/master/lib/roda.rb#L512
# Default implementation of the main route, usually overridden
# by Roda.route.
def _roda_main_route(_)
end
这个函数竟然是空的,什么都不执行。一切竟然就此打住了。 WTF ???
不过注释说了,这也是类似一个接口。他是预留给 Roda.route 覆盖的。他的实现在另一处,在 Roda初始化的时候,就会覆盖这个方法,从而依然可以完成被调用的实名。我们去看看 Roda.route:
# https://github.com/Mark24Code/roda/blob/master/lib/roda.rb#L316
# Setup routing tree for the current Roda application, and build the
# underlying rack application using the stored middleware. Requires
# a block, which is yielded the request. By convention, the block
# argument should be named +r+. Example:
#
# Roda.route do |r|
# r.root do
# "Root"
# end
# end
#
# This should only be called once per class, and if called multiple
# times will overwrite the previous routing.
def route(&block)
unless block
RodaPlugins.warn "no block passed to Roda.route"
return
end
@raw_route_block = block
@route_block = block = convert_route_block(block)
@rack_app_route_block = block = rack_app_route_block(block)
public define_roda_method(:_roda_main_route, 1, &block)
@app = nil
end
route 做的事情确实是除了缓存 block 之外,就是动态的定义了 _roda_main_route 方法。
并且 route 定义在 ClassMethods 部分,他会在 Roda 第一次进行初始化的时候就运行,也就是 define_roda_method(:_roda_main_route, 1, &block) 这句定义的方法会在实例产生之前就绪可用。
但是这里 不是用 define_method 而是 define_roda_method
# https://github.com/Mark24Code/roda/blob/master/lib/roda.rb#L85
def define_roda_method(meth, expected_arity, &block)
if meth.is_a?(String)
meth = roda_method_name(meth)
end
call_meth = meth
# ..... 省略 .....
# 此处做了参数检查
# ...... 省略 ....
call_meth
end
define_roda_method 稍微复杂一点,我简化了一下,简单的说就是如果传入的是Symbol就会直接使用这个方法,如果传入的是字符串会生成唯一的方法名,再使用。还做了一些参数校验的工作。
我们这里 传入的是 :_roda_main_route 相当于直接使用了这个方法。而这个方法的内容就是 route 声明的 block 罢了。
所以我们根据上文的链路可以简单总结下:
像下面的这样的程序,当第一次开始运行的时候,ruby 会先 require 整个 roda 进行 class Roda 的初始化工作。 App 作为 Roda 的子类,在 Roda 中会做一些额外的工作,把 共享变量 复制一份给子类。这个可以在源码中看到。
require "roda"
class App < Roda
route do |r|
r.on "a" do
r.on "b" do
r.on "c" do
# /a/b/c
puts "hello world"
end
end
end
end
end
在初始化 Roda 的过程中,Roda::Base 会作为插件 先在 Roda 的上下文中运行,提供了 实例方法、类方法,分别通过 include、extend 去插入。这部分可以参考 Roda源码分析(一)插件系统。
route 部分相当于运行在 Roda class 上下文中,route 的块,被当做 :_roda_main_route方法进行了注册。
当用户的请求打过来,经过 HTTP Server(可能是 Puma、Thin、WEBrick…) 调用 Rack,Rack再调用 Roda, Road.call 方法实际上返回的是 Roda.new(env)._roda_handle_main_route 而 _roda_handle_main_route 最终转发到了 _roda_main_route 其实就是 route 中声明的块。等于直接运行了 route中定义的块。
好家伙,这跟传球一样,踢来踢去的,终于要到了处理路由的部分了。
那么 树状路由 到底如何处理的呢? 咱们接着往下看吧:
route do |r|
r.on "a" do
r.on "b" do
r.on "c" do
# /a/b/c
puts "hello world"
end
end
end
end
route 代码部分是真实直接被调用的函数。为什么这样说,我们要看看 route 的 block 一旦开始被调用,那么代码就会运行到 第一句 r.on "a", 我们知道 r 其实就是 RodaRequest 实例。这部分应该去关注 RodaRequest 里面 关于 on 方法的定义。 其实 Roda 里面主要是 on 、is 两个方法, on 方法代表着 类似 /path/* 粗匹配。 而 is 方法代表类似 /path 精确匹配。由于我是看过的,所以可以直接横向比较两个。
# https://github.com/Mark24Code/roda/blob/master/lib/roda/request.rb#L207
def on(*args, &block)
if args.empty?
always(&block)
else
if_match(args, &block)
end
end
# .... 省略 他们之间的代码 ...
# https://github.com/Mark24Code/roda/blob/master/lib/roda/request.rb#L162
def is(*args, &block)
if args.empty?
if empty_path?
always(&block)
end
else
args << TERM
if_match(args, &block)
end
end
is 其实比 on 多不了多少。其实看 on 好了比较好理解。可以先看他做了什么,on 的第一个参数 其实就是 Roda 语法里面,填写匹配的一个字段。
r.on "a" do
r.on "b" do
# 匹配 /a/b
end
end
args 就是 “a”,”b” 之类的。如果他是 空字符串,也就是 args.empty? 是 true ,那意味着到头了,匹配到了。直接对 block进行求值。 always 里面做的就是求值返回。不信我们看下:
# .... 省略 他们之间的代码 ...
# https://github.com/Mark24Code/roda/blob/master/lib/roda/request.rb#L495
# Yield to the match block and return rack response after the block returns.
def always
block_result(yield)
throw :halt, response.finish
end
always 里面使用了 Ruby的catch与throw 技巧。如果写的很夸张,路由这部分是个复杂的树结构,throw 可以带着值直接返回到 外部定义的 catch(:halt) 的地方,这个地方我们上面提到过。不信你可以搜一下。这其实就像是 goto 语句。
额外提一嘴,学习编程很多年,我水平不行但是还是看了很多书的,书本上都会提到尽量不要用 goto, 这里用 goto 就非常合适,简直比较巧妙。对于标准、规范这件事不要迷信要辩证看。Linus就喜欢用 goto。当然我们水平比较差的时候,还是老老实实遵守规范。希望我们都可以达到随意使用goto 的水平 :)
PS: 我不重要的观点:
我最近觉得写程序这件事,要有点 灵动感 在里面。要灵动,只有灵动能表达出我内心的意思。不要把自己变成机器一样死板。
随着职业生涯变长,看到过越来越多不是就事论事,实事求是,解决问题的程序员。他们要么畏首畏尾,要么迷信最佳实践。喜欢把书上的印刷字氛围圭臬。喜欢追求符号式的宗教感。喜欢茴字有几种写法,但是缺乏对东西的热爱和洞见。无法区分丑陋与美。
我们要做的是把机器变成人,而不是要把人变成机器。人变成机器那就悲剧了。
is 相比于 on 额外做了一个是否全匹配的检查,以及全匹配插入一个 TERM 的自定义类对象。其实是为了方便后面的 if_match 方法。下面就要讲到。
其实路由匹配,就发生在 is_match 这里面了,终于到这里了。不光你看的要睡着了,我手都要写麻了。
# .... 省略 他们之间的代码 ...
# https://github.com/Mark24Code/roda/blob/master/lib/roda/request.rb#L555
def if_match(args)
path = @remaining_path
# For every block, we make sure to reset captures so that
# nesting matchers won't mess with each other's captures.
captures = @captures.clear
if match_all(args)
block_result(yield(*captures))
throw :halt, response.finish
else
@remaining_path = path
false
end
end
is_match 也做了一点事情,要说下 @captures 就是一个数组存储已经匹配的字符串的,主要是注入给当下要工作的块的。知道一下就好。block_result 做的事情就是把 yield 求值块的返回值正确的加入到 RodaResponse 的实例里,按照 Rack 的要求写入 response, 很好理解。
所以整体的意思就是,如果 match_all (因为 args 可以是个数组,甚至比较复杂的。我们前面只说了 “a”) 全匹配,那么就开始向内求解他的块。敏感的同学能不能意识到,随着 route 书写路由的是一个嵌套的结构,这里相当于一种嵌套式的调用。
简单的说,就拿一路顺利的情况来说, 一旦我们访问的是 “/a/b/c”,Roda 工作起来像什么呢?
route do |r|
r.on "a" do
r.on "b" do
r.on "c" do
# do sth ...
end
end
end
r.on "e" do
r.on "f" do
r.on "g" do
# do sth ...
end
end
end
end
拿 《Mastering Roda》 作者说的,求解的过程就像一个毛毛虫,他首先爬到了 “a”, 接着 匹配到了,就爬到了 “b”, 如此往复,他沿着正确的路线,一直抵达到目标。 而他的工作方式就是匹配,然后开始调用块。逐步向内调用。
块,是Ruby里面的概念,其实就是 lambda 抑或有个名字——匿名函数。 以JavaScript作为类比就是 ` function(){ }` 这个就是一个 函数调用的行为,一级一级往里链式调用。
我们都知道,这种执行栈式的调用,其实是比较快的。他没有复杂的初始化等更加消耗时间的行为。而且很简单粗暴。
这就是Roda巧妙地地方。
说道这里,我都觉得差不多了。大概的概念已经明白了。那么 match_all 发生了什么呢? 猜猜也知道大概做了一些匹配呗。
# .... 省略 他们之间的代码 ...
# https://github.com/Mark24Code/roda/blob/master/lib/roda/request.rb#L600
def match_all(args)
args.all?{|arg| match(arg)}
end
# .... 省略 他们之间的代码 ...
# https://github.com/Mark24Code/roda/blob/master/lib/roda/request.rb#L572
def match(matcher)
case matcher
when String
_match_string(matcher)
when Class
_match_class(matcher)
when TERM
empty_path?
when Regexp
_match_regexp(matcher)
when true
matcher
when Array
_match_array(matcher)
when Hash
_match_hash(matcher)
when Symbol
_match_symbol(matcher)
when false, nil
matcher
when Proc
matcher.call
else
unsupported_matcher(matcher)
end
end
# .... 省略 他们之间的代码 ...
# https://github.com/Mark24Code/roda/blob/master/lib/roda/request.rb#L428
def _match_string(str)
rp = @remaining_path
length = str.length
match = case rp.rindex(str, length)
when nil
# segment does not match, most common case
return
when 1
# segment matches, check first character is /
rp.getbyte(0) == 47
else # must be 0
# segment matches at first character, only a match if
# empty string given and first character is /
length == 0 && rp.getbyte(0) == 47
end
if match
length += 1
case rp.getbyte(length)
when 47
# next character is /, update remaining path to rest of string
@remaining_path = rp[length, 100000000]
when nil
# end of string, so remaining path is empty
@remaining_path = ""
# else
# Any other value means this was partial segment match,
# so we return nil in that case without updating the
# remaining_path. No need for explicit else clause.
end
end
end
match_all 把数组按顺序遍历的匹配,调用的其实是 match ,而 match 方法会根据每个 输入的 matcher 也就是路由里 /a/b/c 里面的比如 “a” 开始做匹配。
我们摘要了最基础的 _match_string 看看具体的匹配策略里面到底做了什么。
看起来好像做了很多事情,其实就是一单匹配,就开始编辑 @remaining_path 这是 RodaRequest 的一个实例变量,用来记录剩余路由的部分。
最后把,所有的 _match_* 都在做编辑 @remaining_path 的工作,并且返回是否匹配的布尔值。
2022.03.13 补充: 再细化一下 r.on、r.is
r.on vs r.is
这里想再单独拿 r.on 和 r.is 讨论一下。
上面的描述可能太过细节。整体看下来还是比较抽象的。然后这里简单的描述下过程。
route do |r|
r.on "a" do
r.on "b" do
r.on "c" do
# /a/b/c
puts "hello world"
end
end
end
end
以此为例说明下,r.on 的工作就是 匹配 arg 这里就是 “a”,”b” 这种路径参数。
如果是 arg 的情况分为几种:
- 无参数,也就是 空值(
nil),这里就被认为是 r.on的终点了,一旦进行到了这步,就会开始对 block求值,并且返回了。 -
一个参数,也就是上面 ‘a’ 这种情况,会进行匹配,匹配中了,会进行 对 block 求值。
这里情况特殊在于,r.on 里面也是一个 block 怎么办?类似于链式调用,再调用子的 block 并等待它的值返回。一直到请求到最内部为止,Roda会以 throw :halt 的方式, 跳出很深的嵌套,直接弹出结果。类似goto。
- 多个参数 ,类似于
r.on "a",Integer,"b"这种,r.on 会使用循环的方式对 args 数组进行挨个匹配,如果匹配成功就会消耗掉@remaining_path,进行下一个匹配。全部正确就 求 block 的值。如果失败了会还原@remaining_path。返回 false
这里不论是哪种情况,匹配失败,都是返回 false
false 不意味着程序被中断,意味着这段代码块被执行完毕。而 false 值也没什么意义,假设这个值在最外层的话,会被人为是 false 返回给 @_response 那么 Roda 会把 false、nil 都解释为 404 NOT found。如果不是最外面一层,仅仅意味着一段 block 的代码被执行完毕。然后就会继续在代码层面,向平级的函数往下继续执行 —— 也就是执行嵌套路由的平行部分。
这个过程有几个显然的结论:
1.想要路由被充分的处理,需要在充分的使用 r.on 进行树状分叉的定义路由。这样才会体现每个节点都调用了 块。
Roda 还可以在公共结点处,共享逻辑。
2.除非 r.on 后面无值,直接进行计算,否则都是 匹配了开始执行块返回结果。所以 r.on 有 /path/to/* 的匹配效果。其实是因为不管有没有匹配完成,匹配到后面,直接运行了块返回的结果。
3.额外 r.is 和 r.on 的区别 —— 终点精确匹配的原理
def on(*args, &block)
if args.empty?
always(&block)
else
if_match(args, &block)
end
end
def is(*args, &block)
if args.empty?
if empty_path?
always(&block)
end
else
args << TERM
if_match(args, &block)
end
end
r.is 插入了 TERM
而在 match 方法中, 字符串、正则、数组等,都要匹配并且编辑 @remaining_path ,但是存在几个匹配的终点。
比如 TERM,false,nil,true 最终程序遇到他们就必须返回。这个作为一切匹配的终结。
r.is 其实就是通过 尾部加入 TERM,比如 r.is "test" 等价于 r.on "test",TERM 进行了一个精确地匹配罢了,因为对于 r.on 来说这个 args 必须完全匹配才会继续下去。
4.方法匹配 r.get, r.post 的原理
def post(*args, &block)
_verb(args, &block) if post?
end
def get(*args, &block)
_verb(args, &block) if is_get?
end
def is_get?
@env["REQUEST_METHOD"] == 'GET'
end
def _verb(args, &block)
if args.empty?
always(&block)
else
args << TERM
if_match(args, &block)
end
end
r.get ,r.post 就是多一步骤判断方法 动词,如果方法不匹配就提前返回了。其他的依然是运行了 r.is 的逻辑,插入了 TERM 作为终点匹配。
5.并列句
r.on "sample" do
# 公共部分
post_list.values.join(" | ")
r.on do
# A 部分
end
r.is Integer do |index|
post_list[index]
# B部分
end
# 也可以返回
end
别忘了route里面的块 就是一段代码而已。如果可以匹配就会不断的更深入的求内部嵌套的块。
而如果 A部分匹配失败了,就像正常代码一样,运行到 B部分匹配。对于路由就是平行关系。
而 A、B 部分运营完了,依然有机会运行到 下部分。
所以这里没有魔法,执行的过程是纯粹的。
这里最差情况寻找到路由是 O(n), 而最好的情况可以得到 O(ln(n))。
还有这里如果没有明显的 return 语句,返回的是最后一个表达式。如果不注意这个,可能会对结果有点意外。
最终写入返回结果
整个过程可以看成这段代码
def _roda_handle_main_route
catch(:halt) do
r = @_request
r.block_result(_roda_run_main_route(r))
@_response.finish
end
end
_roda_run_main_route 中 r 就是我们的route,整个返回值就是我们 route 中块的返回值。
这里有一个疑问,最终结果通过 r.block_result 把结果挂在了 @_request 中,到底最后结果如何传递?
其实是 r.block_result 中调用了 response 这是一个方法,用来返回 @_response, write 方法就是写入 body
def block_result(result)
res = response
if res.empty? && (body = block_result_body(result))
res.write(body)
end
end
然后再回到开头 catch(:halt) 部分,最后 @_response.finish 返回结果。
一切如此平淡,没有什么魔法。
总结
看到这里不容易。至此,我觉得 Roda 的思想已经足够清晰。
树状路由,更像是——我们人为的编写了运行路径一般。路由一旦被响应,就会把路由 “/a/b/c” 传入 RodaRequest 也就是 r 对象,然后开始运行真实的 Ruby 代码,也就是我们书写的 route 部分的 DSL。
一棵树的根节点,一旦不匹配,他的块会直接返回 false 的结果,等于这块不会再继续深入。从而像正常 Ruby 代码一样的运行下面的另一棵树。直到一层一层找到正确的路径,一层一层的执行他内部的块。
一直到匹配完毕,结束了,直接通过 throw 跳出嵌套结构,返回结果。
后记
一直在用摸鱼时间研究学习Ruby。目前很喜欢的语言,有我觉得一些问题,但是瑕不掩瑜。
感谢 Jeremy Evans 的作品。他的坚持和 0 issues 的精神很让我感动。
摸鱼了快一周,记录了结果。不能让我的老板知道。:P
意识流笔记,忽略我的烂字:

