Mark24
用100行Ruby代码模拟JavaScript的Eventloop
前言
大家好,我是Mark24
背景
我们都知道 JavaScript 是单线程的。
今天看到一个有趣的帖子 www.v2ex.com/t/871848,主要是争论JavaScript的优缺点。我看到这个评论觉得很有意思:
@qrobot:
....省略....
多线程下会消耗以下资源
1. 切换页表全局目录
2. 切换内核态堆栈
3. 切换硬件上下文(进程恢复前,必须装入寄存器的数据统称为硬件上下文)
ip(instruction pointer):指向当前执行指令的下一条指令
bp(base pointer): 用于存放执行中的函数对应的栈帧的栈底地址
sp(stack poinger): 用于存放执行中的函数对应的栈帧的栈顶地址
cr3:页目录基址寄存器,保存页目录表的物理地址
......
4. 刷新 TLB
5. 系统调度器的代码执行
....省略.....
这位同学列举了多线程切换的时候发生了什么。 这样给了一种很直观的感受,就是多线程切换的时候发生了很多事情,实际上会比单线程(只需要切换函数上下文)要消耗点更多的资源。
实际上凡是交互的软件,最终都是 单线程模型 + 事件驱动辅助。
从熟悉的浏览器、游戏、应用程序……都是如此。
也有多线程实现的。这里Multithreaded toolkits: A failed dream? (2004) 有很多讨论。
实际上单线程模型是最后的胜出者。
JavaScript 内部单线程处理任务,主要是有一个 EventLoop 单线程的循环实现。
我们可以通过 JavaScript 的表现,反推实现一下 EventLoop。
EventLoop 实现
JavaScript 的行为
我们知道 setTimeout 在 JavaScript 中用来推迟任务。实际上自从 Promise 出现之后,渐渐有两个概念出现在大家的视野里。
- Macrotask(宏任务)
- Microtask (微任务)
setTimeout属于宏任务,而 promise的then回调属于微任务。
还有一个就是 JavaScript 在第一次同步执行代码的时候,是宏任务。
EventLoop的表现是,除了第一次执行结束之后,如果有更高优先级的 微任务总是先执行微任务,然后再执行宏任务。
setTimeout 是一个定时器,很特别的是他在会在计时器线程工作,运行时间之后,回调函数会被插入到 宏任务中执行。计时器线程其实不是 JavaScript虚拟的一部分,他是浏览器的部分。
Ruby 模拟
JavaScript 是单线程的。 Ruby是支持多线程的。我们可以用 Ruby 模拟一个 单线程的核心,和单独的计时器线程,这都是很轻松的事情。
其实我们听到了这个行为 —— 花1分钟大概能想到,EventLoop 的工作模型
- 首先他是一个主循环,这样才能所谓的单线程
- 其次,既然有两种任务,应该是两种队列
- 再者,如果第一次同步代码是宏任务,多半可以代码任务也丢到队列里
我们可以用数组当做 队列。但是 由于存在时间线程,还得用 Thread#Queue 有保障一点。
大概的模型可以画出来,想这个样:
Eventloop Model
(start)
|
init (e.g create TimerThread )
|
sync task (e.g read & run code)
|
|
------------------>
| | -------------
| macro_task --- add timer task --> | TimerThread |
| (Eventloop) | <-- insertjob result --- -------------
| |
| micro_task
| |
| |
<-----------------
|
|
(end)
- 完整的代码仓库 Mark24Code/rb_simulate_eventloop
然后我们大概用100行不到就可以实现如下:
需要说明的是:
1) settimeout 不要用每一个新的线程来模拟,因为一旦多线程,涉及到抢占式回调,其实返回的时间不确定。你的结果是不稳定的。 我们需要单独实现一个计时器线程。
2) 我们通过行为封装,把两边函数写法对照,这样可以复制
运行看结果
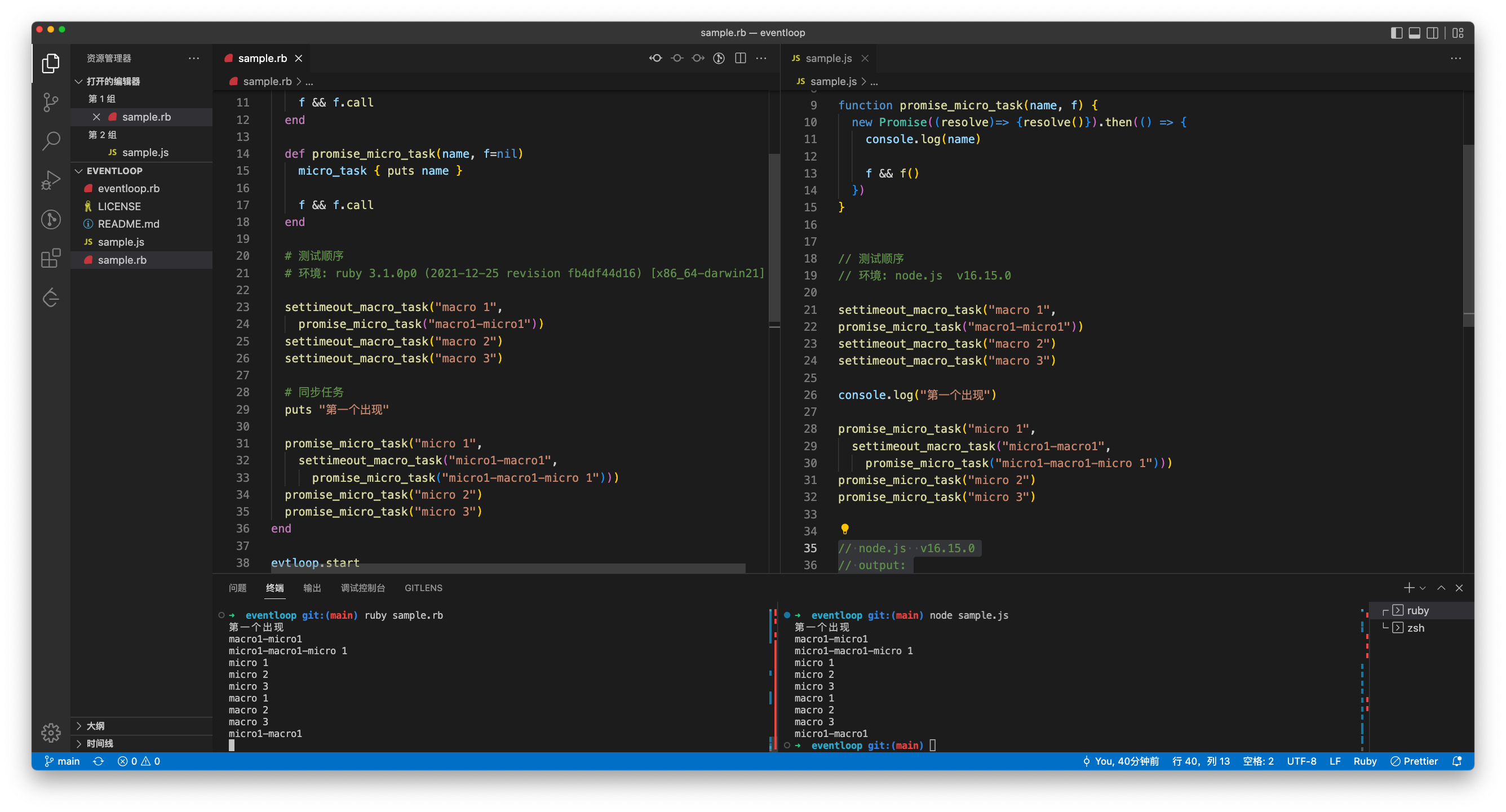
具体实现
# https://github.com/Mark24Code/rb_simulate_eventloop
require 'thread'
class EventLoop
attr_accessor :macro_queue, :micro_queue
def initialize
@running = true
@macro_queue = Queue.new
@micro_queue = Queue.new
@time_thr_task_queue = Queue.new
@timer = Timer.new(@time_thr_task_queue, @macro_queue)
# 计时线程,是一个同步队列
# 会把定时任务结果塞回宏队列
@timer_thx = Thread.new do
@timer.run
end
end
def before_loop_sync_tasks
# do sth setting
@first_task.call
end
def task(&block)
# 这里放置第一次同步任务
#
# 外部书写的代码,模拟读取js
# 提供内部的api
@first_task = -> () { instance_eval(&block) }
end
def after_loop
puts "[after_loop] eventloop is quit :D"
end
def macro_queue_works
while !@macro_queue.empty?
job = @macro_queue.shift
job.call
end
end
def micro_queue_works
while !@micro_queue.empty?
job = @micro_queue.shift
job.call
end
end
def start
begin
before_loop_sync_tasks
while @running
macro_queue_works
micro_queue_works
# avoid CPU 100%
sleep 0.1
end
ensure
after_loop
end
end
# dsl public api
# inner api
def macro_task(&block)
@macro_queue.push(block)
end
def micro_task(&block)
@micro_queue.push(block)
end
def settimeout(time, &block)
# 模拟定时器线程
if time == 0
time = 0.1
end
# 方案1: 用独立分散的线程模拟存在问题
# 抢占的返回顺序不是固定的
# t = Thread.new do
# sleep time
# @micro_queue.push(block)
# end
## !!! 这里一定不能阻塞,一旦阻塞就不是单线程模型
## 有外循环控制不会结束
# t.join
# 方案2: 时间线程也需要单独模拟
# 建立一个时间任务
@time_thr_task_queue.push({
sleep_time: Time.now.to_i + time,
job: -> () { @micro_queue.push(block) }
})
end
end
class Timer
def initialize(task_queue, macro_queue)
@task_queue = task_queue
@macro_queue = macro_queue
end
def run
while (task = @task_queue.shift)
sleep_time = task[:sleep_time]
if sleep_time >= Time.now.to_i
@macro_queue.push(task[:job])
else
@task_queue.push(task)
end
end
end
end
总结
选择单线程的原因是因为
- 结果运行的更快
- 无上下文负担
- 任务队列清晰而又简单
- 非IO密级任务,可以跑满CPU
Nginx、Redis 内部也实现了单线程模型,来应对大量的请求,提高并发。
现在我们大概知道了,浏览器、应用、app、图形界面、游戏……
他们的背后大概是什么样子。 破除神秘感 +1 :D